MI SELECCIÓN DE NOTICIAS
Noticias personalizadas, de acuerdo a sus temas de interés

Agregue a sus temas de interés
A más de cinco décadas de su nacimiento en las universidades de Dartmouth y Carnegie Mellon en Estados Unidos, la llamada ciencia de la Inteligencia Artificial (AI, por sus siglas en inglés) ha venido arrojando avances durante los últimos dos lustros, materializándose todo ello en los algoritmos de Machine Learning (ML) y Deep Learning (DL). Este último período ha implicado superar el llamado “invierno de AI”, apalancándose en los avances tecnológicos de generación y almacenamiento masivo de datos (Big Data) y el incremento exponencial del poder computacional, según la Ley de Moore.
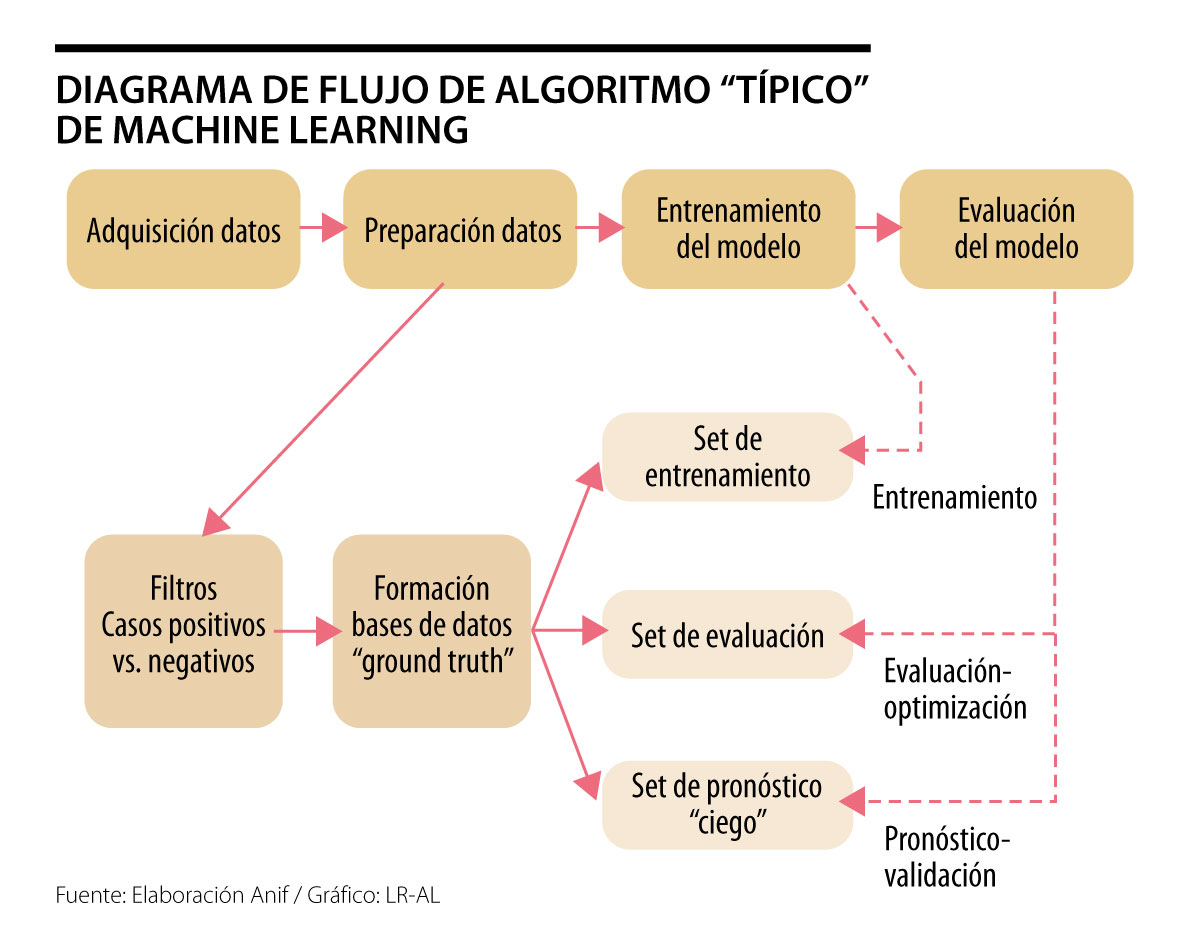
En esta nota se abordan las ventajas potenciales de dichos algoritmos-ML vs. las técnicas de regresión lineal, concluyendo que su ventaja radica en el foco operacional-efectivo ex ante (obviando la necesidad de formulación de modelos - hipótesis). Sin embargo, el “entrenamiento” de dichos algoritmos ML requiere insumos de datos masivos, limitando su aplicabilidad-ventaja comparativa predictiva en algunas esferas macrofinancieras.
La revolución del Ml
En esencia, ML es un método de análisis de datos que automatiza la especificación de modelos de predicción. Dichos procesos de AI se basan en la premisa de sistemas emergentes (a la Hayek) que “aprenden” de los datos mediante la identificación de secuencias patrones; todo ello con mínima intervención humana. Esta nueva vertiente de ML ha implicado avances en el uso de algoritmos autónomos en aplicaciones tan diversas como el manejo de autos (Tesla, Google), recomendaciones de compras-películas (Amazon, Netflix), comerciales (Facebook) y el consabido fenómeno del Fintech.
Todo ello ha implicado un viraje en la naturaleza misma de la programación computacional, pasando de dichos procesos if-then (que suponen complejas tareas de especificación de algoritmos-modelos) hacia métodos de “back propagation” en DL. Este último proceso básicamente evita los problemas de especificación mediante la mímica del comportamiento del cerebro humano de “aprender con ejemplos” (ver Lee, 2018, AI Superpowers).
Un algoritmo de ML (al igual que un “niño”) debe ser entrenado para reconocer un gato mediante ejemplos. En el caso de un niño, ello implica decir la palabra “gato” cada vez que veo un gato (… y el niño, después de suficientes ejemplos hace la asociación por sí solo). En el caso del algoritmo, ello implica exponerlo a millones de fotos con gatos y sin gatos. Con base en esas iteraciones, el algoritmo empieza a reconocer los patrones de pixeles asociados a un “gato”. Dicho de otra manera, este enfoque ML-DL implica transformar el problema desde un proceso paso a paso (¿cuáles son las características de un gato?) hacia uno predictivo (¿será que esta nueva foto -sin labels- tiene asociaciones probabilísticas con los patrones de gatos que el algoritmo ya conoce?).
“repaso” de la regresión lineal
Las técnicas estadísticas de regresión lineal han sido la herramienta econométrica principal durante las últimas décadas, concentrándose la ciencia en el pulimento de dichas técnicas estadísticas. Pero… ¿qué es en verdad lo que hacen estos modelos? A riesgo de simplificar, dicho análisis de regresión básicamente hace una predicción basada en el promedio de lo que ha ocurrido en el pasado. Por ejemplo, una predicción de la probabilidad de lluvia para el día de mañana podría tomar valores de 14% (1/7) si mi conjunto de información fueran las observaciones de la última semana (lloviendo uno de siete días). Dicha técnica se vuelve más poderosa al usar los llamados promedios condicionales, puliendo dichas predicciones al tener en cuenta un contexto mucho más amplio de datos. Ello deriva en predicciones de la forma de P (lluvia) dado un vector Z de variables (invierno vs. verano, nubosidad, humedad del ambiente, etc.). Por ejemplo, un modelo de este tipo debería predecir una P (lluvia/invierno) superior a P (lluvia/verano), pudiéndose complicar terriblemente los cálculos al condicionar por múltiples variables de manera simultánea.
ML vs. regresión lineal
El enfoque de ML es totalmente distinto a dicha regresión lineal en, al menos, dos aspectos fundamentales. En primer lugar, las predicciones basadas en ML pueden ser sesgadas (erróneas en promedio), pero tienden a tener una varianza mucho menor. En otras palabras, cuando se equivocan, no se equivocan por mucho.
En segundo lugar, el desarrollo de un algoritmo predictivo de ML implica, indefectiblemente, demostrar ex ante su éxito en la práctica (o sea que efectivamente predice los datos con los cuales alimento el algoritmo). En cambio, la estimación de una regresión requiere un enfoque teórico previo, lo cual implica alguna intuición conocimiento de las variables explicativas.
En síntesis, los algoritmos de ML tienen evidentes ventajas de flexibilidad operativa vs. sus contrapartes de regresión clásica. Sin embargo, materializar dichas ventajas requiere de una gran cantidad de datos, muchas veces no presentes en las series de tiempo financieras macroeconómicas. En otras palabras, dichas aplicaciones ML pueden ser altamente valiosas a la hora de predecir “recomendaciones de películas-series” en Netflix y compras en Amazon, basadas en millones de calificaciones de usuarios. Sin embargo, su valor agregado en predecir series macrofinancieras mensuales-trimestrales es algo más limitado.








{kind=link}